Building an efficient AI Server
... that doesn't cost you a fortune in electricity bills.

I’ve been running a homelab for a while and wanted to add “AI capabilities”, like running LLM inference with Ollama, image generation with Stable Diffusion and Flux, or TTS with Coqui. However, I didn’t want the upgrade to be expensive, either in hardware costs or electricity bills. So I went down the rabbit hole and came out the other end with an autoscaling on-demand AI server that keeps both performance and energy costs in check!
If you want to skip the discovery journey and just want to see the final architecture, feel free to skip ahead to Pod Autoscaling and Wake on LAN.
Why should it be efficient?
That’s a great question. In Germany, where I live, electricity prices are among the highest in the world, about 35 cents per kWh. My homelab already runs 24/7, so adding another 35 watts of constant draw would mean roughly 300 kWh per year, or about 105€. Beyond the cost, there’s also the benefit of reducing your carbon footprint and improving sustainability.
Hardware selection
For my AI server I went with the following hardware:
- Intel(R) Core(TM) i5-10400 CPU @ 2.90GHz
- 16 GiB DDR4 Memory
- Gigabyte H510M S2H V2
- Nvidia GeForce RTX 4060 Ti
- Some 300W PSU
The combination is not ideal, mainly because the 10th generation Intel CPU only supports PCIe Gen 3, while the RTX 4060 Ti is designed for 8 lanes of PCIe Gen 4, so it will end up running with 8 lanes of PCIe Gen 3. In reality, this is mostly negligible and comes down to approximately 5% reduced performance (from what I’ve read). The base PC I already had lying around, so that’s why it is what it is, and bought the GPU used because it offered 16GB of VRAM at a much lower price than a 4090 or 3090. I could imagine the 5060 Ti could also be a good option. The GPU choice doesn’t matter so much for this build anyway, and you might even see more benefit in power savings when using a higher-end GPU.
How to save power?
I explored several ways to save power. Initially, I wanted the server to run 24/7 like my other machines, but eventually I decided to allow it to sleep when not in use. Here are the main strategies I considered:
- Reaching High Package C-States
- ASPM for the GPU and other PCI devices
- S2 Idle
- S3 Sleep
Reaching high package C-States seemed straightforward at first. You just need to enable the right BIOS options, like Platform Power Management, ErP, ASPM, C-States Control, Package C State Limit -> C10, CPU EIST Function, and others. Then, run sudo powertop --auto-tune and monitor the package C-States with sudo powertop.
Despite all of these BIOS settings and optimizations, my package C-States would never go past C3, so I could never reach those idle power consumptions of 5W and was instead stuck at 20W + 10W from the GPU.
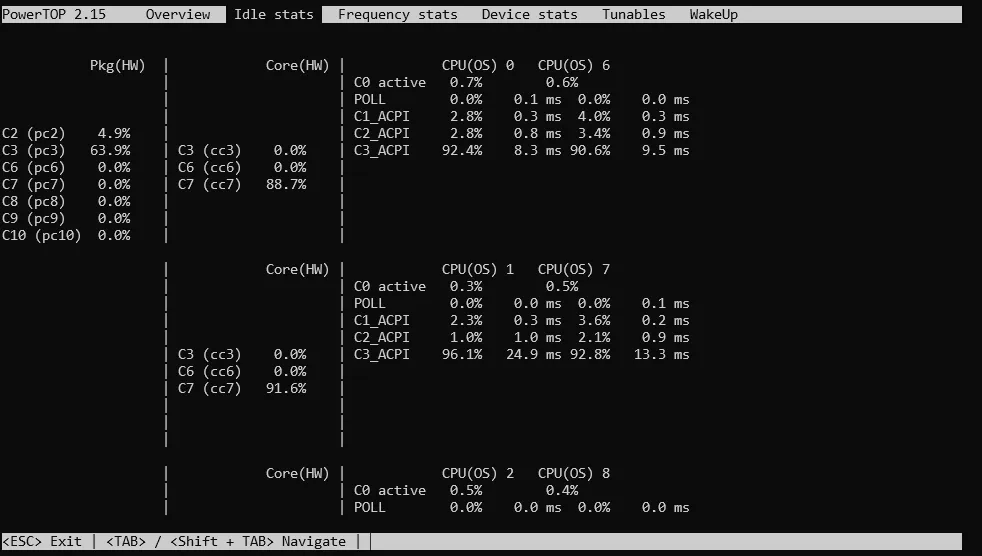
Something in the system was preventing the CPU from reaching lower power C-States. That’s where ASPM comes in.
Active-state power management (ASPM) is comparable to C-States, but for PCIe devices like the GPU or Ethernet controller. If a device, most likely the GPU, isn’t idling properly with ASPM, it can prevent the CPU from entering deeper C-States.
I found this excellent blog post guiding me through various different techniques to troubleshoot ASPM and the package C-States: Forcing ASPM by adding pcie_aspm=force to the GRUB_CMDLINE_LINUX_DEFAULT, alternatively adding pci=nommconf to bypass ACPI tables, and finally even patching the ACPI tables before boot in the UEFI to force support for ASPM.
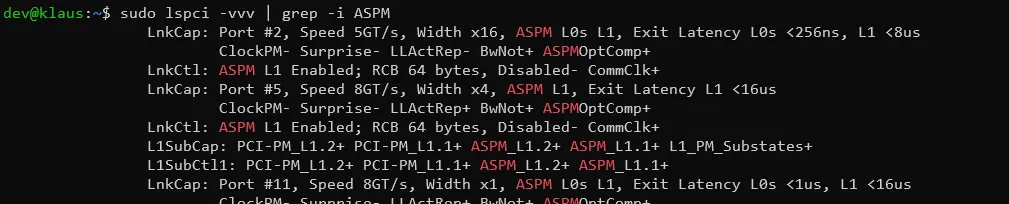
In the end, I had theoretically working ASPM on all PCI devices, but still didn’t manage to get below C3. So I changed strategies: instead of chasing idle power savings, I decided to use a sleep state (like laptops do) and drop to 1.3W, instead of the roughly 10W I would most likely get with idle C-States, while accepting a small cold start time for any AI services.
“S2idle” (Suspend-to-Idle) is a low-power state in Linux where the system freezes user space, puts I/O devices into low-power states, and allows processors to enter deeper idle states. Wake-up time is usually near-instant, which would have been perfect for my use case. Unfortunately, just like with the C-States, something kept waking the machine up immediately, so S2idle wasn’t an option.
So eventually I decided to go for the good old S3 Sleep (Suspend to RAM). This was fairly easy to achieve and still had a manageable cold start time of roughly 3 seconds. All you had to do was write mem into the /sys/power/state file to put the server to sleep and use Wake-On-Lan (sudo ethtool -s eth0 wol g) to wake it back up.
Joining the Cluster
After finally finding my power saving mode of choice, it was time to join the node to my homelab Kubernetes cluster.
Drivers and Container Runtime
In order to enable the node for GPU usage, a couple of preparation steps had to be taken first (based on this guide and the K3s docs):
- Install Drivers
- Install NVIDIA Container Toolkit
- Install NVIDIA device plugin for Kubernetes
- Add Taints and Tolerations to Workloads
Installing the drivers is as simple as running:
sudo ubuntu-drivers --gpgpu installFor installing the NVIDIA Container Toolkit, a few more steps are involved:
First install the GPG key and repository:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listThen update your package list with sudo apt-get update, and then install the toolkit:
sudo apt-get install -y nvidia-container-toolkitNext, configure the container runtime to use the NVIDIA runtime. For containerd, this is done with:
sudo nvidia-ctk runtime configure --runtime=containerdAfterwards, it’s a good idea to restart the node.
Now, install K3s on the node to join the cluster. After installation, K3s should automatically detect the NVIDIA runtime. You can check this by running the following and looking for “nvidia” among the runtimes:
$ kubectl get runtimeclassNAME HANDLER AGEcrun crun 189dlunatic lunatic 189dnvidia nvidia 189dnvidia-experimental nvidia-experimental 189dslight slight 189dspin spin 189dwasmedge wasmedge 189dwasmer wasmer 189dwasmtime wasmtime 189dwws wws 189dNext, you need to install the NVIDIA device plugin for Kubernetes. This can be done by applying the manifest. This enables requesting GPUs in your workloads.
resources: limits: nvidia.com/gpu: 1 # requesting 1 GPUAnd finally, I added a taint to the node to prevent workloads from being scheduled on it that don’t need the GPU (apart from necessary daemonsets, e.g., for networking). This should prevent any workload disruptions when the node is put to sleep.
kubectl label nodes <node-name> nodetype=gpukubectl taint nodes <node-name> gpu:NoSchedulePod Autoscaling and Wake on LAN
To bring it all together, I use a combination of Pod Autoscaling with KEDA or Sablier and Wake-On-Lan to wake the AI node, and a custom controller I built called Kubesnooze, which suspends the node when all pods are scaled to zero.
Here’s how the final system works, using Ollama as an example:

-
The user sends his request to access Ollama to the Ingress Controller (Traefik). This route is configured with the Wake-On-Lan Plugin.
apiVersion: traefik.io/v1alpha1kind: Middlewaremetadata:name: klaus-wolnamespace: kubesnoozespec:plugin:traefik-wol:HealthCheck: http://kubesnooze.kubesnooze.svc.cluster.local:8081/healthzStartUrl: http://192.168.0.138:8080/api/wakeup/computer/gpunodeStartMethod: GETNumRetries: 15RequestTimeout: 5
So before the request proceeds, it needs to pass through this middleware. The middleware is configured to check the health probe endpoint of Kubesnooze, running on the GPU node. Naturally, if the GPU node is down, the health probe will be unhealthy.
- Since the GPU node is down, the middleware wants to wake it up. This is achieved by sending a Wake-On-Lan magic packet. However, the magic packet cannot be sent directly from Traefik or the middleware, nor from the Kubernetes cluster itself, because all of them run in pods which use the container network interface. Magic packets, however, can only be sent from the same network as the target host. To solve this, I run a WOL REST Server on my NAS as a container in Host Network Mode. As you can see in the YAML above, the middleware sends the HTTP request to this WOL REST Server.
- The WOL REST Server then sends the actual magic packet to the GPU node and wakes it up.
- This will spin up the server and with it Kubesnooze, which is running as a DaemonSet on this node. You can see an example manifest here. Since Kubesnooze is now running, the health probe will now succeed and the Wake-On-Lan middleware allows the request to access Ollama to proceed.
- The request will proceed to either KEDA or Sablier (whichever is configured for the workload). The main difference between the two is WebSocket support (e.g., for ComfyUI), since when I built this system the Keda HTTP Addon did not support WebSockets. But it is being worked on, so it might be supported in the future, making both a viable option. Either way, they will scale up the deployment from 0 to 1, and then forward the request further to the running deployment.
- Now we can access the running Ollama deployment as we usually would.
- When you’re done working with Ollama and don’t send any more requests, the deployment will scale back to 0 after 5 minutes (configurable in both KEDA and Sablier if you want your deployment to stay alive for longer). Kubesnooze detects the scale down event, and if all tracked deployments are scaled to 0 for another 5 minutes (also configurable), it will send the suspend command (
memto/sys/power/state) to the host and put the node back to sleep.
And that’s it. This way, the server will start and sleep on demand whenever you try to access any (AI) workload that needs the GPU, provided you can live with a little cold start time (in my experience, usually not more than 30 seconds).
Note: If suspend isn’t working as expected, it might be the nvidia driver preventing it. You can add
options nvidia NVreg_PreserveVideoMemoryAllocations=0to/etc/modprobe.d/nvidia.confto disable this behavior (Might have to create the file first). Then runsudo update-initramfs -uand reboot.
Conclusion and Next Steps
I have been running with this setup for about 6 months now, and I must say I’m quite satisfied with it. It is working very reliably and hasn’t failed on me yet, except for the one early incident when I forgot to make Wake-On-Lan persistent on the node and it didn’t work anymore after a reboot. I use it to run several generative AI workloads, e.g., LLMs with Ollama, TTS with Kokoro and Piper, and image generation with ComfyUI. For now, I use these in an experimental setting only, so the on-demand scaling works perfectly for this. I can’t yet tell if it will still work well for scheduled or unsupervised tasks requiring AI. Another issue I very rarely encounter is that the cold start and subsequent loading of the model in Ollama takes longer than 30 seconds, causing the system (e.g., OpenWebUI) to cancel the request as a 504 (Gateway Timeout). But this is only an issue on the first request, of course, and all following requests (or retries) work flawlessly after.
There are still a few improvements that can be made to this system. Personally, I’d like to move the server to my rack, as right now, it’s still sitting under my desk in a regular mid-tower case. By now, I have enough confidence in it that I don’t need to sit right next to it babysitting its behavior. For Kubesnooze, I have a few other improvement ideas: Right now, it does just enough for my single AI server setup, but if you were to run multiple GPU servers, it would need to be a bit more flexible: detecting workloads to monitor by annotation on the deployment, rather than a static list. Then, for those workloads, the node they are scheduled on can be determined dynamically, and once a node has no scheduled deployments anymore, only this node could be sent to sleep. Waking up could be trickier, since you wouldn’t know in advance which node would be scheduled, but you could just wake both, and the inactive one would go back to sleep after 10 minutes.
Another improvement would be integrating Kubesnooze with the cluster autoscaler API, for better handling of sleeping nodes. Currently, a sleeping node shows as NotReady, which triggers warnings or errors for Daemonsets that are supposed to run there.
That’s it. I hope you found this post useful and maybe even inspiring to build your own AI server at home. If you have any questions or suggestions, feel free to reach out via (blog@flomon.de).
Ciao Kakao.